After reading Patrick Stox’s post on Search Engine Land about Fixing Historical Redirects, I was inspired to start using Wayback Machine’s API within one of my Google Sheets. After a little playing with some formula’s, I developed the Discover Lost URLs Google Sheet.
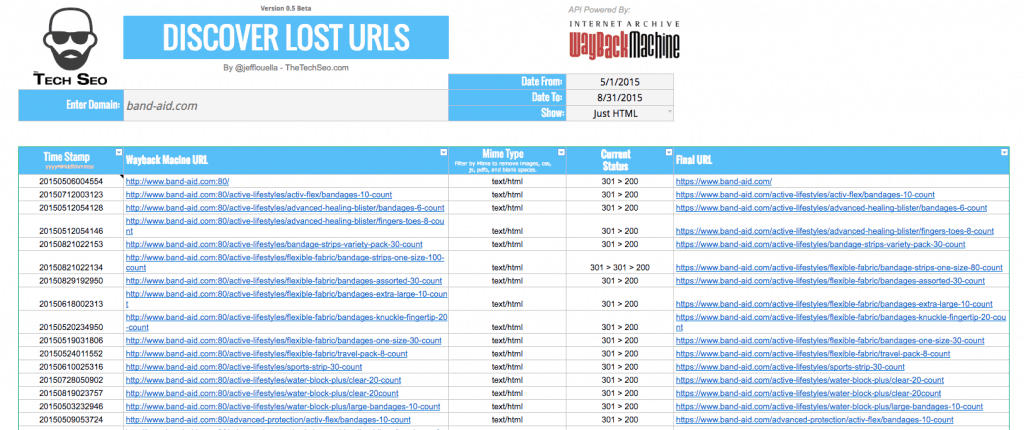
How The Sheet Works
Step 1: Enter Domain
Enter a domain name that you are looking to audit. The URL can be entered in several ways.
- domain.com
- subdomain.domain.com
- www.domain.com/sub-folder/
Once the URL is entered, the sheet will begin to populate.
Step 2: Modify Dates
Set the “Date From” and “Date To” fields to pull the URLs that are in the Wayback Machine’s database.
Step 3: Choose What To Show
By default, the Wayback API spits out all URLs. This includes images, CSS, JS, and HTML. The sheet is set to show “Just HTML” by default. To show all, drop down the selection box to “All”
Reading the Sheet
Time Stamp: The Time Stamp column shows the date the URL was in the index in the format of yyyyMMddhhmmss.
Wayback Machine URL: This is the URL from the database
Mime Type: This indicates whether the URL is for an HTML page, CSS file, JS file, etc…
Current Status: This is a custom function that was written to pull back the URLs status code. If there is a redirect in place, it will follow the redirect and post the path as “301 > 200”. If it is is a redirect chain, it will pull in the chain too, such as “301 > 301 > 302 > 404”
Final URL: This URL is the current final destination of the older Wayback URL. This is great to see where SEO value is being lost.
Download The Discover Lost URLs Google Sheet Now!
Sheet Limitations
Google Sheets can choke up on large amounts of data. I set the API to only pull in 20,000 rows max. I think it will struggle at that, depending on ram and browser. If the sheet is running too slow, try to do a few runs with a smaller date range.
When we find the broken links, How can we fix, resolve them?
Thanks,
This tool only discovers them. To fix them, you need to created 301 redirect from the old URL to the new URL. How to do that depends on what server you are using.
Thank you very much for this post. Regarding the current status custom function, could you please explain the meaning and difference of the following cases:
301 > 200
301 > 301 > 200
301 > 301 > 301 > 200
301 > 301 > 303
301 > 302 > 200
301 > 302 > 404
301 > 303
301 > 404
302 > 404
error
blank
Actually what i want to understand is the sequence logic.
Thanks a lot in advance,
Regards,
P.
So sorry I didn’t see your response until now. These are the status codes of the requests it takes to get to the final destination. For example 301 > 301 > 200 means the main URL redirected twice with a 301 before it ended at a 200. Hope that helped.
I may be a bit late to the party, but would it be possible to tweak the script a bit in order to display an additional column with the actual archive url?
https://web.archive.org/web/20120709000203/http://www.website.com/homepage.html
^ For example. Look forward to hearing from you soon. Thanks!
-Tyler
Thank you for this article on wayback machine. Difficult to find reliable services.